📄 Introduction
The next breakthrough in AI isn’t a new architecture — it’s the language quietly powering everything beneath it.
Most conversations in AI, ML, Data Science, Big Data, and Quantum Computing revolve around models or hardware. Rarely do we talk about the language layer that runs the pipelines, preprocessors, kernels, and distributed systems — yet that layer increasingly defines performance, safety, and scalability.
As workloads grow, engineering teams are realizing that the biggest gains don’t come from tweaking models, but from strengthening the foundation under them. And that foundation is increasingly built with Rust — now appearing in tokenizers, data engines, inference runtimes, distributed compute frameworks, and even quantum simulators.
This article explores why traditional languages are hitting their limits, and how Rust is quietly emerging as the backbone of modern compute-heavy systems.
Where Python, C++, and JVM Hit Their Breaking Point
AI/ML/Data workloads have outgrown the assumptions older languages were designed for. The problem isn’t the languages — it’s the scale and complexity of today’s systems.
Python — fast to write, slow to scale
Python is perfect for prototyping, but hits limits in heavy systems:
- The GIL blocks true multithreading
- Real speed comes from C/C++ extensions, not Python itself
- Numerical code runs slower without native bindings
- Scaling Python often means adding more hardware, not improving code
- Tools like NumPy, PyTorch, TensorFlow are not pure Python
Python stays — it just shouldn’t carry the weight of the heaviest code paths. It remains the best language for experimentation, but not for the performance-critical 10% of code that does 90% of the work.
The irony: most “Python speed” is actually C++ speed, wrapped in Python convenience.
C++ — unmatched speed, unmatched complexity
C++ delivers performance, but creates challenges at system scale:
- Memory safety issues increase maintenance cost
- Concurrency requires extreme caution
- Debugging production issues is expensive
- Large C++ codebases become difficult to evolve
C++ gives you power, but also a loaded gun.
JVM Languages — Reliable, but not low-level enough
Java/Scala/Kotlin power large distributed systems, but:
- Garbage Collection introduces unpredictable pauses
- Higher memory overhead than native languages
- Not ideal for performance-critical AI kernels
Good for orchestration, not for fine-grained compute paths
Modern Workloads Outgrew Their Languages
Today’s infrastructure needs:
- C++-level speed
- Python-like safety and ergonomics
- Predictable concurrency
- Direct control over memory
- Easy interop with Python ecosystems
Every major language solves part of the problem — but none solve all of it. That gap between capability and need is exactly where Rust is taking over.
The industry doesn’t need a faster model — it needs a safer foundation.
Rust Enters the Chat — And Quietly Rewrites the Stack
As AI and data workloads scale, teams need something faster than Python, safer than C++, and lighter than JVM-based systems. Rust sits precisely in that gap.
Rust delivers the low-level control needed for performance-critical components — but without the memory-safety issues that traditionally come with system programming. Its compiler enforces rules that prevent data races, unsafe sharing, and hard-to-debug crashes, which makes it a natural fit for workloads that push hardware limits.
What makes Rust particularly compelling for modern AI and data systems is its ability to offer consistent, predictable performance without a garbage collector, while still allowing safe parallel execution. This combination is extremely rare, yet exactly what heavy tokenizers, vector engines, inference runtimes, and distributed compute layers need today.
And unlike many “faster” alternatives, Rust doesn’t require teams to abandon Python. Instead, it integrates cleanly with Python ecosystems through tools like PyO3 and maturin — letting Python remain the interface, while Rust takes over the parts where speed and reliability matter the most.
In short: Rust wasn’t created for AI, ML, or Big Data… but the demands in these fields now align perfectly with the guarantees Rust provides. That’s why Rust keeps showing up quietly inside the tools developers use every single day — often without them realizing it.
How Rust Is Rewriting the Modern Compute Stack
Rust isn’t replacing entire ecosystems — it’s replacing the performance-critical pieces inside them. Below are real, verifiable examples across each domain.
Environment Note
All Python code examples in this post were executed inside a Conda environment using the Anaconda Prompt, with the required libraries installed via pip — including transformers, tokenizers, scikit-learn, pandas, polars, duckdb, and qiskit. This ensures that all examples run consistently across systems.
Miniconda (recommended) also provides a Conda-enabled terminal and supports all the same environment operations — without requiring an Anaconda account. It is lightweight and ideal for development setups.
Click the arrows to view the images.
Let’s start with the front door of every NLP pipeline — tokenization.
🔤 AI Tokenization: Where Rust Already Rewrites the Fastest Layer
Python: Hugging Face Tokenizers
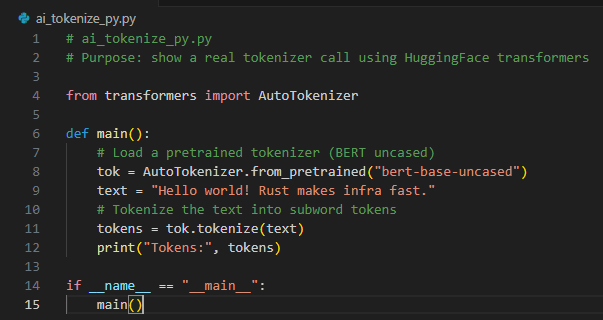
Hugging Face tokenizers split text into learned subword units using pretrained vocabularies — the same logic behind models like BERT and RoBERTa. They handle everything—from vocabulary to wordpiece rules—making tokenization accurate and consistent for AI and NLP tasks.

Click the arrows to view the images.
| Code Line / Block | Explanation |
|---|---|
from transformers import AutoTokenizer |
Imports the factory used to load pretrained tokenizers from the Hugging Face library. |
def main(): |
Defines the program’s entry point. |
tok = AutoTokenizer.from_pretrained("bert-base-uncased") |
Loads the pretrained BERT tokenizer and downloads vocabulary files on first use. |
text = "Hello world! Rust makes infra fast." |
Defines the input text that will be tokenized. |
tokens = tok.tokenize(text) |
Applies the tokenizer to produce subword tokens using BERT’s learned vocabulary and rules. |
print("Tokens:", tokens) |
Displays the resulting token list. |
if __name__ == "__main__": main() |
Standard guard to run main() when executed directly. |
Most people don’t realize that the fastest part of Hugging Face tokenizers is already Rust.
Rust: Regex-based Tokenizer
Rust’s regex-based tokenizer is extremely fast and lightweight — perfect for custom preprocessing stages or embedded NLP systems where learned tokenizers are unnecessary.
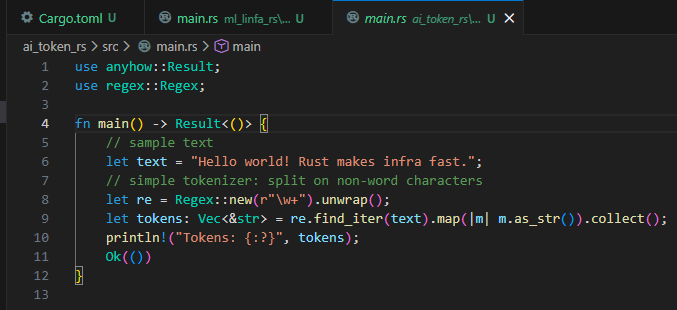

Click the arrows to view the images.
| Code Line / Block | Explanation |
|---|---|
use anyhow::Result; |
Provides a convenient Result type for handling errors cleanly in main. |
use regex::Regex; |
Brings in the regex crate for pattern-based token extraction. |
fn main() -> Result<()> { |
Defines main and returns a Result to allow ? error propagation. |
let text = "..." |
Defines the input text that will be tokenized. |
let re = Regex::new(r"\w+").unwrap(); |
Compiles a regex that matches sequences of alphanumeric characters. |
let tokens: Vec<&str> = re.find_iter(text).map(...).collect(); |
Iterates over all regex matches and collects each token as a string slice. |
println!("Tokens: {:?}", tokens); |
Prints the extracted token list for inspection. |
Ok(()) |
Returns successful program termination. |
Key Difference: Hugging Face vs Regex
| Code Line | Explanation |
|---|---|
Python (HF tokenizer):tokens = tok.tokenize(text) |
Uses a pretrained, learned tokenizer (WordPiece/BERT) that applies vocabulary rules and subword segmentation derived from large-scale training data. |
Rust (Regex tokenizer):re.find_iter(text)...collect() |
Uses a simple handcrafted regex to split text by word patterns; no vocabulary, subword logic, or learned behavior. |
Once we understand how text is broken into machine-friendly pieces, the next step is teaching models to learn from data — which brings us to Machine Learning.
🤖 Machine Learning: When Python Prototypes but Rust Produces
Python: Scikit-Learn
Scikit-Learn provides a rich set of classical ML algorithms with simple APIs. Logistic Regression, SVMs, clustering, pipelines — everything is ready to use with just a few lines of code.
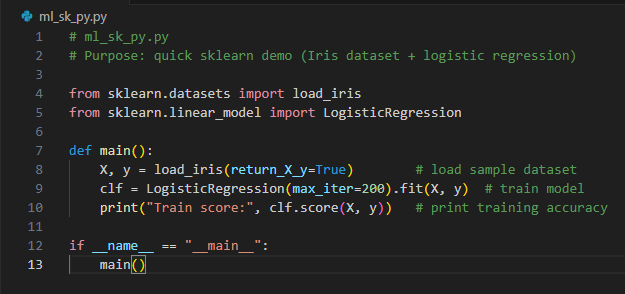

Click the arrows to view the images.
| Code Line / Block | Explanation |
|---|---|
from sklearn.datasets import load_iris |
Imports the function used to load the Iris dataset. |
from sklearn.linear_model import LogisticRegression |
Imports the logistic regression classifier from scikit-learn. |
X, y = load_iris(return_X_y=True) |
Loads feature matrix X and label vector y directly. |
clf = LogisticRegression(max_iter=200).fit(X, y) |
Creates a logistic regression model and trains it, using a higher iteration limit for reliable convergence. |
print("Train score:", clf.score(X, y)) |
Computes and prints training accuracy on the dataset. |
Rust: Linfa
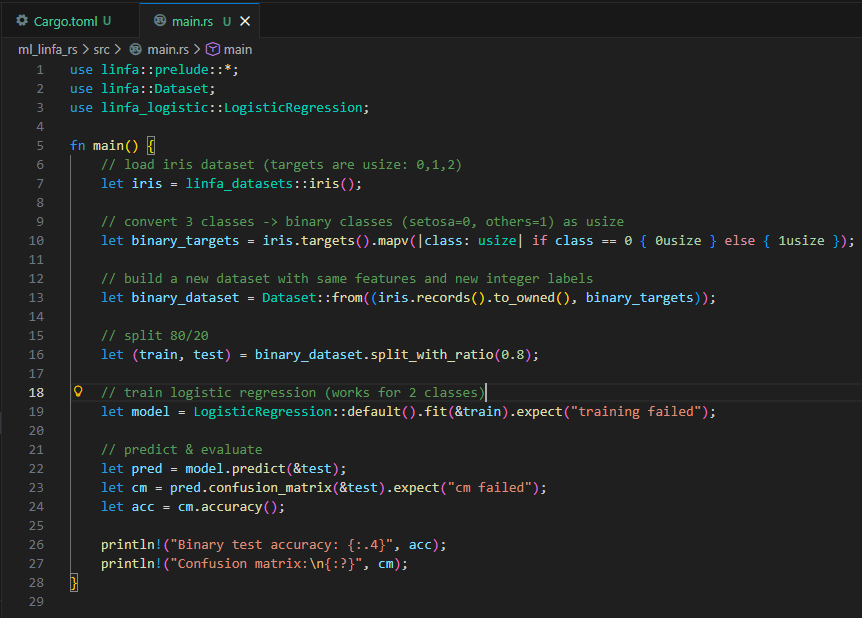
Linfa mirrors Scikit-Learn but in Rust. It brings safe, fast, and reliable ML building blocks. While evolving, it already supports clustering, linear models, datasets, and metrics — with Rust’s performance and safety benefits.
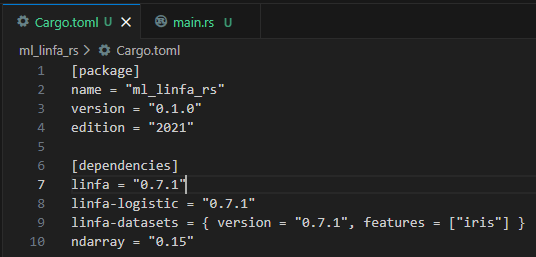
Click the arrows to view the images.
| Code Line / Block | Explanation |
|---|---|
use linfa::prelude::*; |
Imports traits like Fit and Predict needed for model training. |
use linfa::Dataset; |
Provides the dataset structure containing features and labels. |
use linfa_datasets; |
Gives access to built-in datasets like Iris. |
use linfa_logistic::LogisticRegression; |
Imports the logistic regression model implementation. |
let iris = linfa_datasets::iris(); |
Loads the Iris dataset with features and integer labels. |
let binary_targets = iris.targets().mapv(...); |
Converts the 3-class labels to 2 classes because LINFA’s logistic regression is binary-only. |
let dataset = Dataset::from((iris.records().to_owned(), binary_targets)); |
Reconstructs a dataset with original features and new binary labels. |
let (train, test) = dataset.split_with_ratio(0.8); |
Splits dataset into training and test subsets. |
let model = LogisticRegression::default().fit(&train)?; |
Trains a logistic regression model using default settings. |
let pred = model.predict(&test); |
Generates predictions for the test set. |
let cm = pred.confusion_matrix(&test)?; |
Builds a confusion matrix comparing predictions and ground truth. |
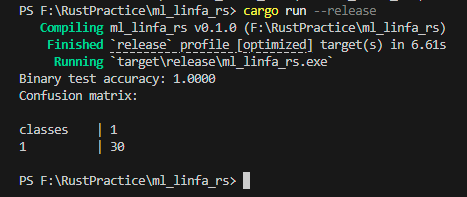
println!("Accuracy: {:.4}", cm.accuracy()); |
Prints classification accuracy. |
Rust’s ML ecosystem is younger than Python’s, but its correctness guarantees make it attractive for production-grade, low-level ML components.
Key Difference: Scikit-Learn vs Linfa
| Code Line | Explanation |
|---|---|
Python (sklearn):clf = LogisticRegression().fit(X, y) |
Trains logistic regression directly on feature matrix X and label vector y. Sklearn automatically handles multiclass classification without additional preprocessing. |
Rust (LINFA):let model = LogisticRegression::default()... |
Trains logistic regression on a Dataset struct containing both features and labels. Requires explicit error handling and supports only binary classification, so labels must be preprocessed beforehand. |
Once a model is trained, real pipelines shift back to the data — cleaning it, transforming it, joining it, aggregating it, and preparing it for further stages.
📊 Data Science: Where Rust Turns DataFrames Into Engines
Python: Pandas
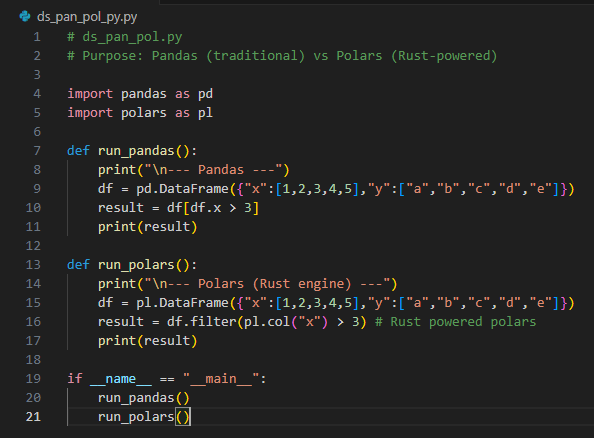
Pandas is the go-to library for tabular data. It provides intuitive operations like filtering, grouping, merging, and reshaping, making data analysis quick and simple.
Click the arrows to view the images.
| Code Line / Block | Explanation |
|---|---|
import pandas as pd |
Imports the Pandas library and assigns it the alias pd. |
df = pd.DataFrame({"x":[1,2,3,4],"y":["a","b","c","d"]}) |
Creates a DataFrame with two columns: numeric x and string y. |
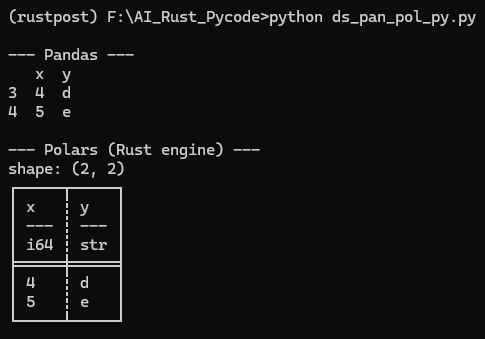
print(df[df.x > 3]) |
Applies boolean indexing to filter rows where x > 3 and prints the resulting DataFrame. |
Python (Rust-powered): Polars
Polars brings Rust’s performance to Python through its blazing-fast columnar engine. It lets you use DataFrame expressions similar to Pandas, but with massively improved speed.
| Code Line / Block | Explanation |
|---|---|
import polars as pl |
Imports Polars Python bindings, which execute operations using the Rust Polars engine. |
df = pl.DataFrame({"x":[1,2,3,4],"y":["a","b","c","d"]}) |
Creates a DataFrame in Polars with the same structure as the Pandas example. |
print(df.filter(pl.col("x") > 3)) |
Filters rows where x > 3 using Polars’ expression engine and prints the filtered DataFrame. |
Rust: Native Polars
In Rust, Polars is fully native. You get the same DataFrame API as Python, but with direct Rust execution, zero overhead, and full type safety — ideal for high-performance pipelines.
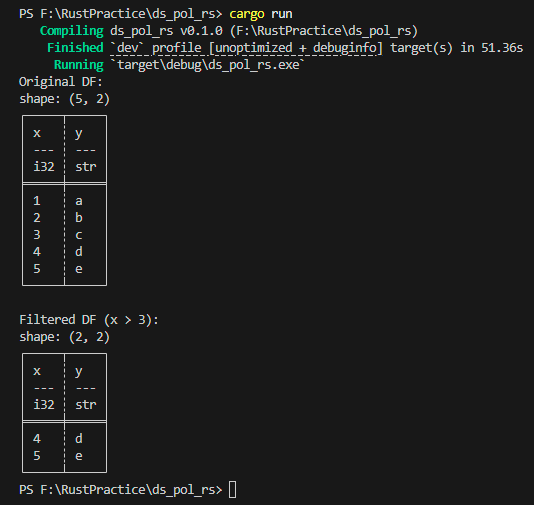
Click the arrows to view the images.
| Code Line / Block | Explanation |
|---|---|
use polars::prelude::*; |
Imports Polars core types such as DataFrame, LazyFrame, col, and expression utilities. |
let df = df![ ... ]?; |
Creates a DataFrame from Rust slices, equivalent to pl.DataFrame({...}) in Python. |
println!("Original DF:\n{}", df); |
Prints the original DataFrame before any transformations. |
df.lazy() |
Converts the eager DataFrame into a LazyFrame, enabling optimized expression-based operations. |
.filter(col("x").gt(3)) |
Applies a filter expression to keep only rows where x > 3. |
.collect()? |
Executes the lazy query and returns the result as a new DataFrame. |
println!("Filtered DF:\n{}", filtered); |
Prints the final filtered DataFrame. |
Ok(()) |
Returns a success value from the Rust program. |
Key Difference: Pandas vs Polars (Rust engine) vs Polars (Native engine)
| Code Line | Explanation |
|---|---|
Pandas:result = df[df.x > 3] |
Uses boolean indexing on the DataFrame; straightforward but not optimized for large datasets or parallel execution. |
Python Polars (Rust engine):result = df.filter(pl.col("x") > 3) |
Executes a Polars expression using the Rust engine, offering higher performance and more SQL-like transformations. |
Rust Polars (native):let filtered = df.lazy().filter(col("x").gt(3)).collect()?; |
Uses the same expression model as Python Polars but runs natively in Rust with no interpreter overhead and full compile-time safety. |
Polars isn’t just faster than Pandas — it’s fundamentally different. Pandas is row-based and mutable, while Polars is columnar and optimized for parallel execution, making Rust a natural host.
As datasets grow beyond a few million rows, DataFrames alone aren’t enough — we need true analytical engines that can run SQL efficiently.
🏢 Big Data: When DataFrames Aren’t Enough
Python: DuckDB
DuckDB is an in-process analytical database often called the “SQLite for Analytics.” It supports SQL queries directly on Parquet/CSV files without any external server.

Click the arrows to view the images.
| Code Line / Block | Explanation |
|---|---|
import duckdb |
Imports the DuckDB library, a fast in-process analytical SQL engine. |
con = duckdb.connect() |
Creates an in-memory database connection for running SQL queries. |
con.execute("CREATE TABLE t AS SELECT * FROM (VALUES ...) AS v(id, val)") |
Creates a small table t using literal VALUES to populate columns id and val. |
rows = con.execute("SELECT * FROM t WHERE id > 3").fetchall() |
Executes a SQL query and retrieves all matching rows into a Python list. |
print("Query result:", rows) |
Prints the results of the executed SQL query. |
Rust: DataFusion
DataFusion is Rust’s native columnar query engine, powered by Apache Arrow. It brings SQL execution, parallel processing, and a full analytical pipeline — all embedded inside your Rust application.
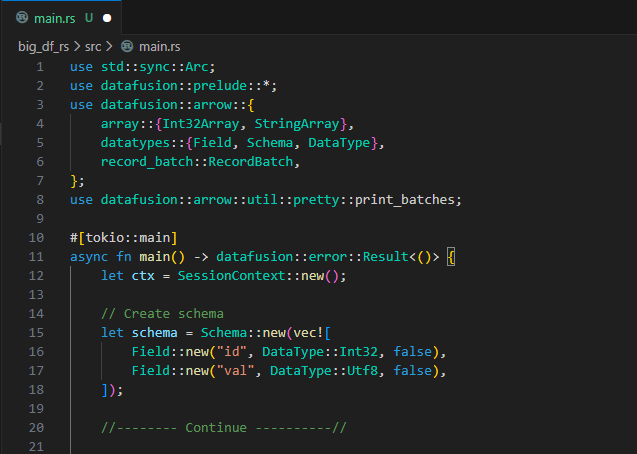
Click the arrows to view the images.
| Code Line / Block | Explanation |
|---|---|
use std::sync::Arc; |
Brings in Arc for shared, reference-counted column arrays. |
use datafusion::prelude::*; |
Imports SessionContext and other DataFusion SQL execution helpers. |
use datafusion::arrow::{ array::{…}, datatypes::{…}, record_batch::RecordBatch }; |
Imports Arrow array types, data types, and RecordBatch, the core structures for columnar storage. |
let ctx = SessionContext::new(); |
Creates a SQL execution context, similar to establishing a DuckDB connection. |
Schema::new(vec![ Field::new(...), ... ]) |
Defines the table schema by specifying column names and their corresponding data types. |
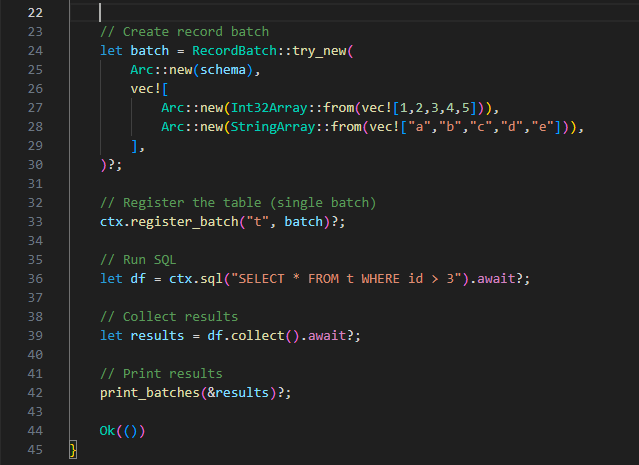
RecordBatch::try_new(schema, columns)? |
Creates an in-memory RecordBatch containing columnar arrays and the associated schema. |
Arc::new(Int32Array::from(vec![1,2,3,4,5])) |
Builds the integer id column as an Arrow columnar array. |
Arc::new(StringArray::from(vec!["a","b","c","d","e"])) |
Builds the string val column as an Arrow columnar array. |
ctx.register_batch("t", data)? |
Registers the RecordBatch as a table named t, equivalent to CREATE TABLE in DuckDB. |
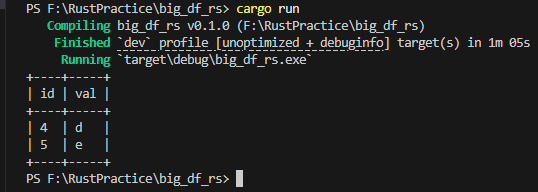
ctx.sql("SELECT * FROM t WHERE id > 3").await? |
Executes SQL against DataFusion’s query engine using async execution. |
df.collect().await? |
Collects query results into Arrow RecordBatch output. |
println!("{:?}", batch); |
Prints each returned batch, representing the result rows. |
Ok(()) |
Returns a standard successful result from the Rust program. |
Key Difference: DuckDB vs DataFusion
| Code Line | Explanation |
|---|---|
DuckDB (Python):rows = con.execute("SELECT * FROM t WHERE id > 3").fetchall() |
Executes SQL using DuckDB’s embedded engine and returns results as Python rows. |
DataFusion (Rust):let df = ctx.sql("SELECT * FROM t WHERE id > 3").await?; |
Executes SQL using DataFusion’s Arrow-backed engine and returns results as Arrow RecordBatch structures. |
DuckDB is incredible for Python, but DataFusion lets developers embed an analytical engine directly into systems, turning Rust applications into full SQL compute layers.
After scaling up through DataFrames and SQL engines, the next frontier takes us beyond bits entirely — into quantum states, amplitudes, and probabilistic computation. And that brings us to quantum computing.
⚛️ Quantum Computing: Where Rust Meets the Strange World of Qubits
Python: Qiskit
Qiskit allows you to build quantum circuits, apply quantum gates, simulate measurement outcomes, and visualize results. It’s the most widely used toolkit for quantum programming.
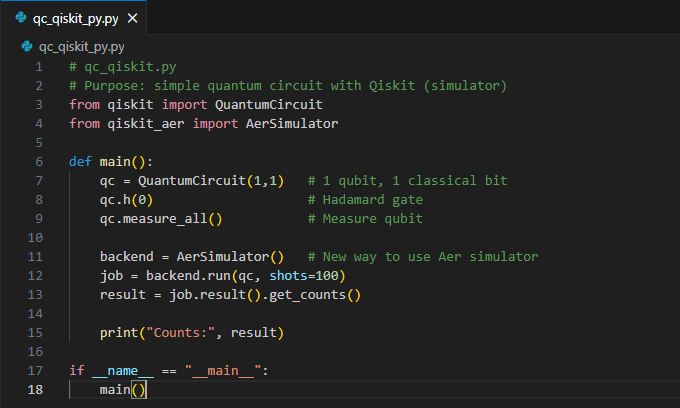

Click the arrows to view the images.
| Code Line / Block | Explanation |
|---|---|
from qiskit import QuantumCircuit, Aer, execute |
Imports Qiskit components: circuit builder, Aer simulator backend, and the execution helper. |
qc = QuantumCircuit(1,1) |
Creates a 1-qubit quantum circuit with 1 classical bit for measurement outputs. |
qc.h(0) |
Applies a Hadamard gate to qubit 0, placing it into a superposition state. |
qc.measure_all() |
Measures all qubits and stores the results in classical bits. |
backend = Aer.get_backend('aer_simulator') |
Selects the local Aer simulator backend for fast circuit simulation. |
res = execute(qc, backend, shots=100).result().get_counts() |
Executes the circuit 100 times (shots) and retrieves measurement counts. |
print("Counts:", res) |
Prints the measurement histogram showing how often each outcome occurred. |
Rust: Manual Quantum Simulator
Rust doesn’t yet have a mature Qiskit-equivalent crate, but we can simulate qubits manually using amplitudes, Hadamard transforms, and measurement logic. This gives a clear view of how qubits evolve under quantum operations.
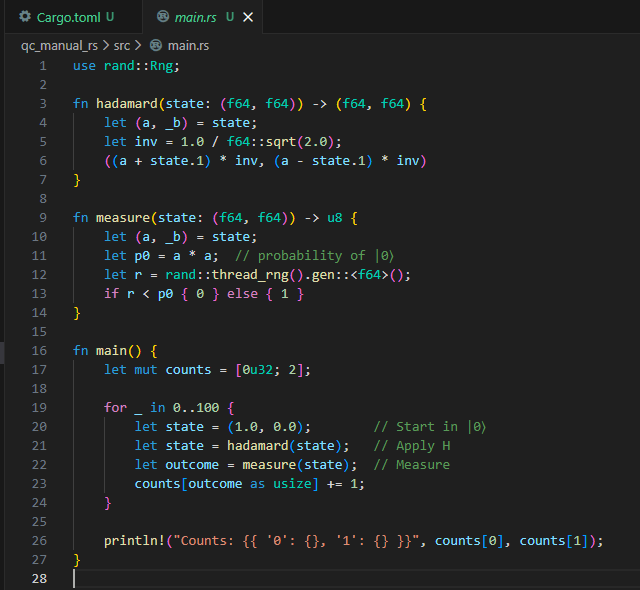
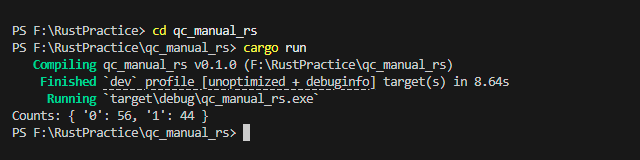
Click the arrows to view the images.
| Code Line / Block | Explanation |
|---|---|
use rand::Rng; |
Imports random-number generation utilities for simulating probabilistic measurements. |
fn hadamard(state: (f64, f64)) -> (f64, f64) |
Defines a function that applies the Hadamard gate to a 1-qubit state represented as amplitudes (α, β). |
let (a, _b) = state; |
Extracts the α and β amplitudes; β is ignored using _b to avoid warnings. |
let inv = 1.0 / f64::sqrt(2.0); |
Computes 1/√2, the normalization factor of the Hadamard transformation. |
((a + state.1) * inv, (a - state.1) * inv) |
Applies the Hadamard matrix: produces new amplitudes ((α+β)/√2, (α−β)/√2). |
fn measure(state: (f64, f64)) -> u8 |
Simulates a measurement of the qubit in the computational basis. |
let p0 = a * a; |
Computes probability of measuring | 0⟩ as α² (and | 1⟩ as β²). |
let r = rand::thread_rng().gen::<f64>(); |
Generates a random number in [0,1) to determine the measurement outcome. |
if r < p0 { 0 } else { 1 } |
Returns 0 if r < probability of | 0⟩; otherwise returns 1. |
let mut counts = [0u32; 2]; |
Initializes counters for measurement outcomes 0 and 1. |
for _ in 0..100 |
Runs 100 measurement shots, matching Qiskit’s shots=100. |
let state = (1.0, 0.0); |
Starts the qubit in the | 0⟩ state, represented as amplitudes (1.0, 0.0). |
let state = hadamard(state); |
Applies the Hadamard gate to produce a superposition state. |
let outcome = measure(state); |
Collapses the state probabilistically into either | 0⟩ or | 1⟩. |
counts[outcome as usize] += 1; |
Increments the count for the observed measurement outcome. |
println!(...) |
Prints the final measurement counts after all shots. |
Key Difference: Qiskit vs Rust: Built-in Gates vs Manual Amplitude Math
| Code Line | Explanation |
|---|---|
Qiskit (Python):qc.h(0) |
Applies a predefined Hadamard gate provided by Qiskit’s quantum circuit abstraction. |
Manual Simulation (Rust):let state = hadamard(state); |
Computes the effect of the Hadamard gate manually by transforming the qubit’s amplitude pair (α, β). |
Rust’s ecosystem is evolving quickly.
- To ensure all sample programs compile without errors, specific crate versions as published on crates.io is used at the time of writing.
- Matching the exact versions helps avoid compatibility issues, especially in domains where Rust libraries are still emerging (AI, ML, Big Data, Quantum).
Working through the final domain — Quantum Computing — we’ve seen how Rust can model even the most abstract systems with precision and safety. But once we step away from experiments and demos, a natural question appears:
What actually changes when teams adopt Rust in real engineering?
This takes us into the next section.
Architecture Shifts: When Teams Outgrow Their Old Stack
Switching to Rust doesn’t just swap a language — it reshapes system design.
-
Safety shifts to compile time.
Bugs that once appeared in production—nulls, races, memory leaks—are eliminated before the code runs. -
Systems become more modular.
Rust’s ownership model naturally pushes teams toward small, clean, composable components instead of sprawling frameworks. -
Heavy compute moves closer to the metal.
Critical workloads migrate into Rust, while Python/JS shrink into thin orchestration layers. -
Performance becomes architectural, not incidental.
Zero-cost abstractions and predictable concurrency reduce latency, cut cloud costs, and simplify scaling.
In short, Rust shifts teams from reacting to failures to designing systems that avoid them entirely.
These shifts are meaningful in theory — but they matter even more in production. The next section looks at real companies and systems where Rust isn’t just a choice, but an advantage.
Rust in the Wild: Companies Using It at Scale
Rust isn’t just academically interesting — it’s running inside some of the most demanding systems on earth.
🔹 Cloud Infrastructure
- AWS Firecracker — Micro-VM engine behind Lambda & Fargate, written in Rust.
- Cloudflare Pingora — Next-gen proxy engine replacing Nginx at massive scale.
- Microsoft — Rust in Windows components and cloud service hardening.
🔹 High-Performance Backends
- Discord — High-traffic services rewritten in Rust for concurrency + stability.
- Dropbox Magic Pocket — Rust for storage engine safety and reliability.
- Figma — Real-time collaboration backend performance boosted with Rust.
🔹 Safety-Critical + Systems Work
- Meta (Facebook) — Rust in infrastructure and internal tools requiring safe concurrency.
- Amazon (beyond AWS) — Internal Rust adoption for memory-safe services.
- Mozilla — Performance-critical browser components using Rust.
🔹 Open-Source Ecosystem
- Tokio / Hyper — Async networking backbone for countless production apps.
These aren’t side projects. They’re core production systems — proving Rust’s impact far beyond benchmarks or blog posts.
Conclusion — Why Rust Will Power the Next Wave of AI Infrastructure
Python remains unmatched for exploration and rapid experimentation.
Rust solves a different problem: execution at scale.
As systems grow, teams need software that is fast, memory-safe, efficient, and predictable under extreme load. The companies above already rely on Rust to deliver exactly that.
Rust’s ecosystem moves quickly, and crates require attention to versions and compatibility — but once a project is set up correctly, it offers reliability and performance that are hard to match.
Across every domain we explored — tokenization, ML, dataframes, analytics engines, simulation — one pattern stood out:
Python helps us explore. Rust helps us build.
The future of AI will still speak Python at the top…
…but it will increasingly run on Rust underneath.
More Rust work — and the next chapter of the Teacher Assistant App — are coming soon. Stay tuned.